Handling extreme response style
Following a response I gave on stats.stackexchange.com about the analysis of respondents who always answer the most extreme responses, I finally decided to investigate the topic of extreme response style with greater care.
See the full thread. My main points were that FA applies for attitude items as it does for other kind of measurement instrument, although treating Likert items as continuous data is a long-standing debate. Other models (IRT, SEM, etc.) apply as well. Now, the fact that some respondents may systematically highlight an extreme response style, that is they always select the response categories on the extreme of the scale (e.g., “totally agree” or “totally disagree”), may strongly bias items parameters (whether it be loadings or difficulty).
Background
Ceiling and floor effects are well-know effects in quality of life reports. They simply reflect the fact that most of the times people are well-being, to a few exceptions (those patients that are really sick or are truly depressed, for example). Usually, these items are removed from the scale because they carry very little information; in other words, they have a very low discriminative power although they may seem to enhance scale reliability through their systematic high correlation with summated scale score. This phenomenon generally results from a large proportion of respondents, which differs from cheating effects or things like that which are generally the results of minority of subjects. And this latter case is the one that seems to be of interest here.
Now, the point is that most of psychometric approaches for constructing scale focus at the item level (ceiling/floor effect, decreased reliability, bad item fit statistics, etc.), but when one is interested in how people deviate from what would be expected from an ideal set of observers/respondents, I think we must focus on person fit indices instead. Such χ2 statistics are readily available for IRT models, like INFIT or OUTFIT mean square, but generally they apply on the whole questionnaire. Moreover, since estimation of items parameters rely in part on persons parameters (e.g., in the marginal likelihood framework, we assume a gaussian distribution), the presence of outlying individuals may lead to potentially biased estimates and poor model fit.
As proposed by Eid and Zickar (2007), combining a latent class model (to isolate group of respondents, e.g. those always answering on the extreme categories vs. the others) and an IRT model (to estimate item parameters and persons locations on the latent trait in both groups) appears a nice solution. Other modeling strategies are described in their paper (e.g. HYBRID model, see also Holden and Book, 2009).
Likewise, unfolding models may be used to cope with response style, which is defined as a consistent and content-independent pattern of response category (e.g. tendency to agree with all statements). In the social sciences or psychological literature, this is know as Extreme Response Style (ERS). References (1–3) may be useful to get an idea on how it manifests and how it may be measured.
Detecting perfect scores
Hereafter, I am interested in showing how a subsample of “extreme respondents” might impact the quality of the underlying scale. I shall assume a unidimensional construct, for the sake of simplicity. But it should easily extend to the case of multi-scale questionnaire. Rather than simulating response to Likert item (not so easy, in fact), I will just use data on attitude to the environment, included in the ltm package. The data set (N=291) is comprised of a set of six items coded on a three-point scale: (1) LeadPetrol Lead from petrol, (2) RiverSea River and sea pollution, (3) RadioWaste Transport and storage of radioactive waste, (4) AirPollution Air pollution, (5) Chemicals Transport and disposal of poisonous chemicals, (6) Nuclear Risks from nuclear power station.(11)
I happen to load the data as follows:
data(Environment, package="ltm")
apply(Environment, 2, function(x) table(x)/sum(table(x)))
About 10% of the respondents (N=30) were selected at random and get a 0 score, meaning “not very concerned”. Given that the majority of answers are on the other extreme of the scale (between 52 and 80%), this may be seen as a cluster of “atypical” individuals, who are saying they are not concerned while most of people generally agree that such factor might have a great impact on the environment.
ers.subj <- sample(1:nrow(Environment), 30)
Env.num <- sapply(Environment, as.numeric)
Env.num[ers.subj, ] <- 2
We can check that the scale is unidimensional, which would otherwise not motivate the use of an unidimensional IRT model. This is roughly checked from the distribution of the eigenvalue computed through an PCA, where we superimposed those coming from random data. The picture below (left panel) clearly suggest that unidimensionality holds.
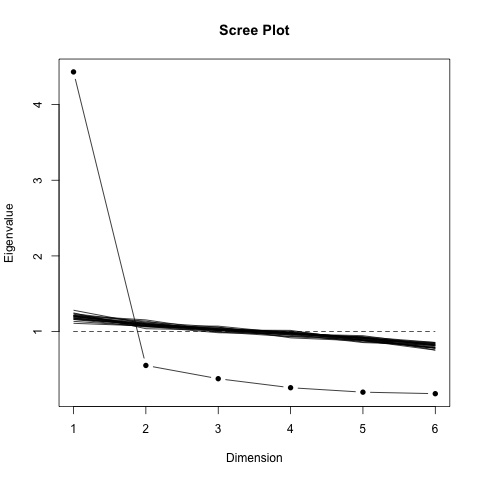
I initially thought of estimating person parameters using the eRm package(12) because it has a nice interface and offers several model to handle polytomous items (partial credit and rating scale models). However, estimation is based on CML and person parameters are not computed for so-called zero or perfect scores. Hence, I have to rely on MML and I choose to base my analysis on the Graded Response Model (GRM), with items considered as equally discriminant (constrained GRM).
grm.fit <- grm(Env.num, constrained=TRUE)
theta.est <- factor.scores(grm.fit)
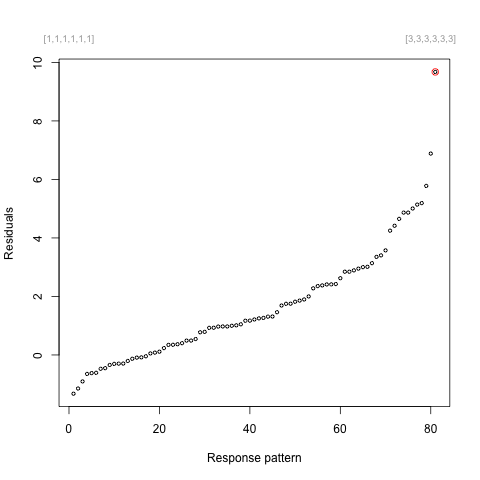
plot(residuals(grm.fit)[,“Resid”])
Now, let’s look at the residuals of the fitted model (figure above, right), and especially at those response patterns like [3,3,3,3,3,3] (or, equivalently, a total score of 18). It appears that the value for this specific response pattern (highlighted in red in the figure below) is quite extreme, with a residual > 9.5.
Another example can be found in the MischPsycho package which includes a function called cheat() that allows to detect unexpected (too similar) response patterns.
References
- Hamilton, D.L. (1968). Personality attributes associated with extreme response style. Psychological Bulletin, 69(3): 192–203.
- Greanleaf, E.A. (1992). Measuring extreme response style. Public Opinion Quaterly, 56(3): 328-351.
- de Jong, M.G., Steenkamp, J.B.E.M., Fox, J.-P., and Baumgartner, H. (2008). Using Item Response Theory to Measure Extreme Response Style in Marketing Research: A Global Investigation. Journal of marketing research, 45(1): 104–115.
- Morren, M., Gelissen, J., and Vermunt, J.K. (2009). Dealing with extreme response style in cross-cultural research: A restricted latent class factor analysis approach.
- Moors, G. (2003). Diagnosing Response Style Behavior by Means of a Latent-Class Factor Approach. Socio-Demographic Correlates of Gender Role Attitudes and Perceptions of Ethnic Discrimination Reexamined. Quality & Quantity, 37(3): 277–302.
- de Jong, M.G. Steenkamp J.B., Fox, J.P., and Baumgartner, H. (2008). Item Response Theory to Measure Extreme Response Style in Marketing Research: A Global Investigation. Journal of Marketing Research, 45(1): 104–115.
- Javaras, K.N. and Ripley, B.D. (2007). An “Unfolding” Latent Variable Model for Likert Attitude Data. JASA, 102(478): 454–463.
- Slides from Moustaki, Knott and Mavridis, Methods for detecting outliers in latent variable models.
- Eid, M. and Zickar, M.J. (2007). Detecting response styles and faking in personality and organizational assessments by Mixed Rasch Models. In von Davier, M. and Carstensen, C.H. (Eds.), Multivariate and Mixture Distribution Rasch Models, pp. 255–270, Springer.
- Holden, R.R. and Book, A.S. (2009). Using hybrid Rasch-latent class modeling to improve the detection of fakers on a personality inventory. Personality and Individual Differences, 47(3): 185–190.
- Brook, L., Taylor, B. and Prior, G. (1991) British Social Attitudes, 1990, Survey. London: SCPR.
- Mair, P. and Hatzinger, R. (2007). CML based estimation of extended Rasch models with the eRm package in R. Psychology Science, 49(1), 26-43.