Org exports
Each time I check my RSS feeds, I come across some nice posts about how folks are using Emacs together with Org mode. I have a dozen of channels that are mostly around Emacs (e.g., Irreal or Sacha Chua), so this comes to no surprise after all. I’m not an heavy user of Org agenda, but this is just because I’m no strong planner. And I have almost no deadline nowadays. However, I’ve come to appreciate writing using Org mode, better than Markdown for text documents larger than, say, blog posts.
Some of my previous posts were about blogging, managing Bibtex records, but this one is more like A text-based workflow for taking note. After two years of using Org mode, here is what’s left: I use Org mode to manage a simple TODO list, a log book, a multi-language notebook for running quick stuff with Babel, an annotated list of Bibtex records, and to write small tutorials or reports.
Regarding the Org markup itself, I find it more coherent and definitely more robust — think of nested item lists, line breaks or image insertion in a list.1 Once rendered into Emacs, it’s no longer apparent that we are dealing with a markup language. Look and see how beautiful Org document are with little customization (basically, the ones that come with Doom Emacs):
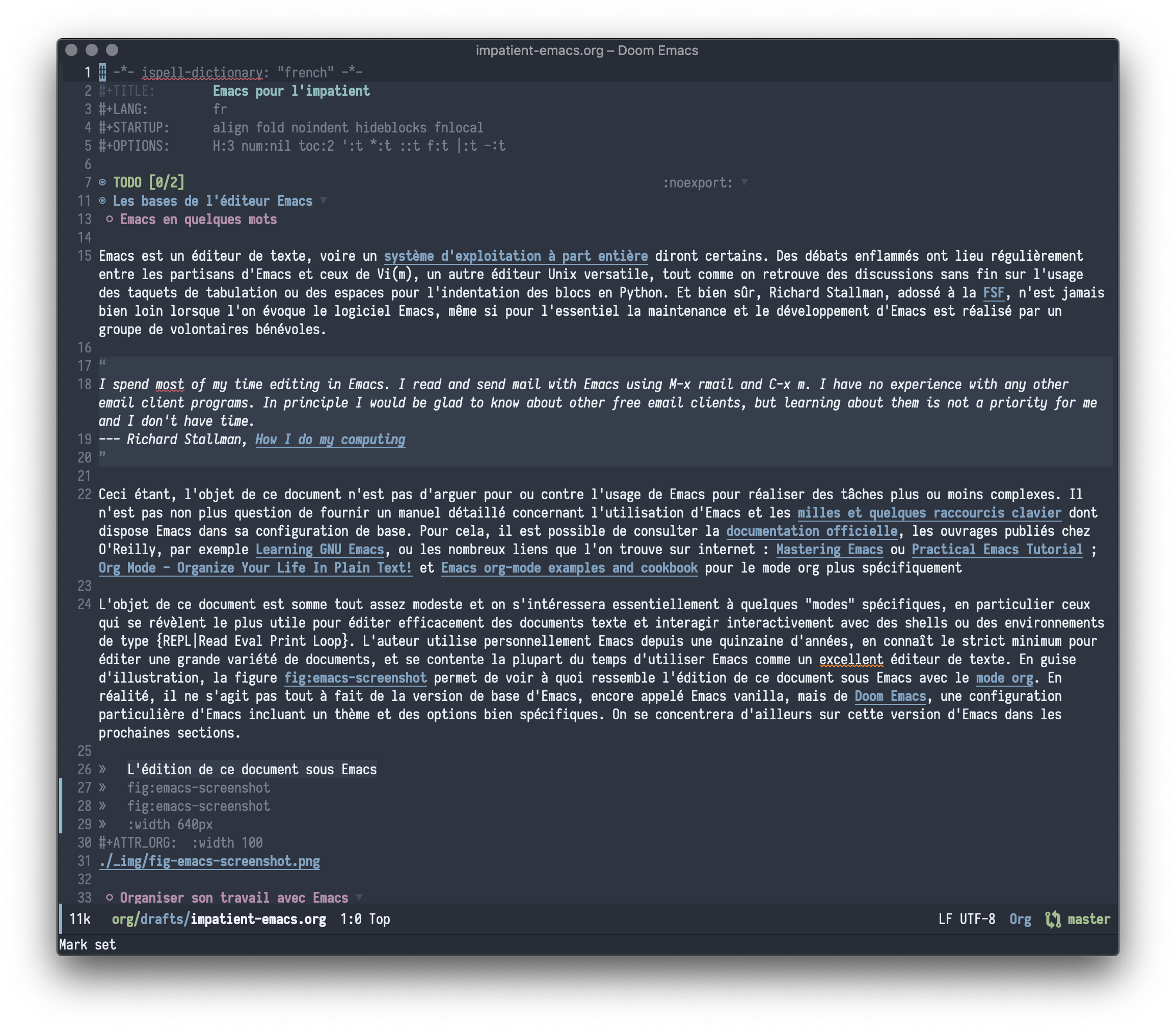
Of course, Markdown mode for Emacs also comes with kind of a “concealing” featuring (which works better than in Vim sometimes), but there’s no comparison when it comes to managing links and images, or even to navigate between headers, IMHO. Furthermore, now that Github renders Org documents like it did for years with Markdown files, we also have a nice way to display our raw files online. But there’s more. Indeed, one of the nicest feature of Emacs + Org is the possibility of using Pandoc as a front-end for exporting Org documents. I first started using default HTML export, but I soon came to realize that using Pandoc provides far better rendering options. Below is the same document exported as an HTML page using a custom Github-like CSS:
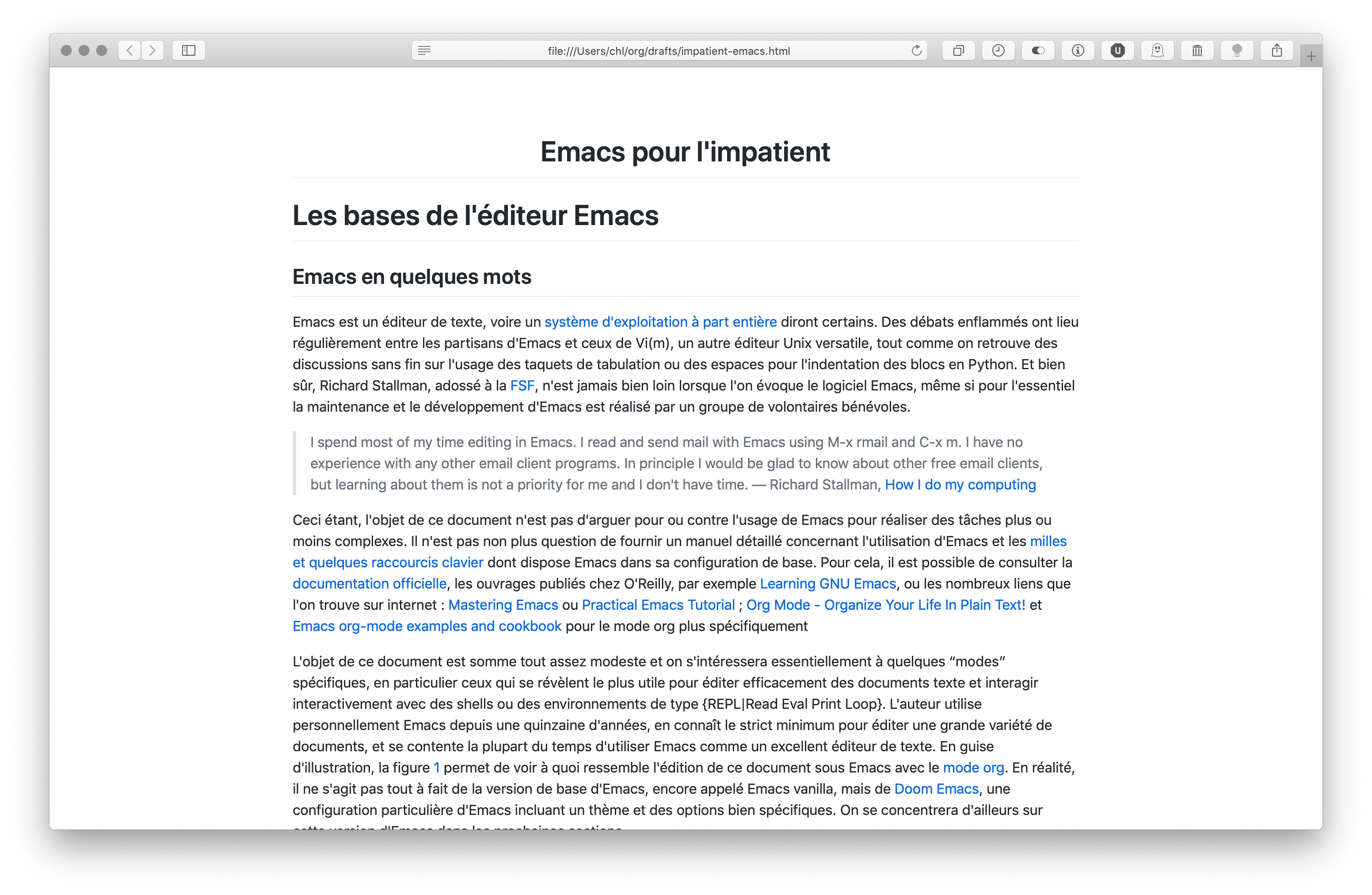
Here is what I have in my Emacs init file:
(setq org-export-with-author nil
org-export-with-creator nil
org-html-postamble nil
org-html-head "<link rel=\"stylesheet\" type=\"text/css\" href=\"_assets/github.css\" />"
org-latex-pdf-process '("latexmk -pdf -f -outdir=%o %f")
org-pandoc-options-for-html5 '((section-divs . t)
(bibliography . "/Users/chl/org/references.bib")
;; https://is.gd/lt21EQ
(template . "/Users/chl/.pandoc/templates/GitHub.html5")))
Nothing really fancy, but this is useful to keep Org header simple enough. I could probably use some kind of template since I always use the same options, but I have a little (ya)snippet that insert everything for me:
# -*- mode: snippet -*-
# name: Header block for HTML tutor
# key: tutor
# condition: t
# --
# -*- ispell-dictionary: "french" -*-
#+TITLE: ${1:The title}
#+LANG: fr
#+STARTUP: align fold noindent hideblocks fnlocal
#+OPTIONS: H:3 num:nil toc:2 ':t *:t ::t f:t |:t -:t
$0
It is also possible to specify Pandoc options directly in the header, e.g.
#+TITLE: ${1:The title}
#+DATE: `(insert (format-time-string "%d %B, %Y"))`
#+OPTIONS: num:nil H:2 ^:t |:t
#+PANDOC_OPTIONS: template:nil
#+PANDOC_OPTIONS: number-sections:t
#+PANDOC_OPTIONS: csl:~/.pandoc/csl/pnas.csl
#+ABSTRACT: $2
$0
The Github template that I use works pretty well for HTML, while for PDF output I rely on the Eisvogel template. But most importantly, using Pandoc means that I can insert Bibtex reference the Markdown way, e.g. @blah2011 or [@blah2011], and I no longer have to rely on ox-bibtex, which is what I was using when writing my Stata Starter Kit (unfinished for a long time). In sum, whether I use Markdown or Org, I can manage my Bibtex entries in the same way. And since this is Org, we can also add a “TODO list” at the top of the document and add a :noexport: tag so it won’t be printed in the final output.
In recent version of Doom Emacs, the centralization of Org exports has been removed. I found it nice that everything is stored under a masked directory (.export/) in the Org root directory, but I can understand that this became quite difficult to maintain this feature with the growing number of exporters.
-
I know the lack of standardization of Markdown (or its many flavors like GFM or Multimarkdown) makes it pretty hard to parse and validate by a machine. ↩︎