Tech Review / October 2018
Here is the (not so) monthly tech newsletter for October. Please note that other link-only items are available in my latest bag of tweets.
According to Wikipedia, probabilistic programming refers to a programming paradign “designed to describe probabilistic models and then perform inference in those models.” I am still on my way to give Anglican a more serious try in the future, but in the meantime, here is the book to read on arXiv: An Introduction to Probabilistic Programming, written by Jan-Willem van de Meent, Brooks Paige, Hongseok Yang, and Frank Wood. Interestingly, the authors decided to use an abstract language similar in syntax and semantics to Anglican for their illustrations, which is not surprising since Frank Wood designed the Anglican PPL.
Zip trees have recently been proposed as a new form of randomized binary search trees, which constitutes an alternative to more classical balanced binary search tree structures. Binary search trees can be implemented in Clojure without much pain. However, a zip tree differ from the classical treap by the fact that priority ties are resolved by favoring smaller keys, whereby the parent of a node has rank greater than that of its left child and no less than that of its right child, while insertions and deletions are handled with unzipping and zipping.
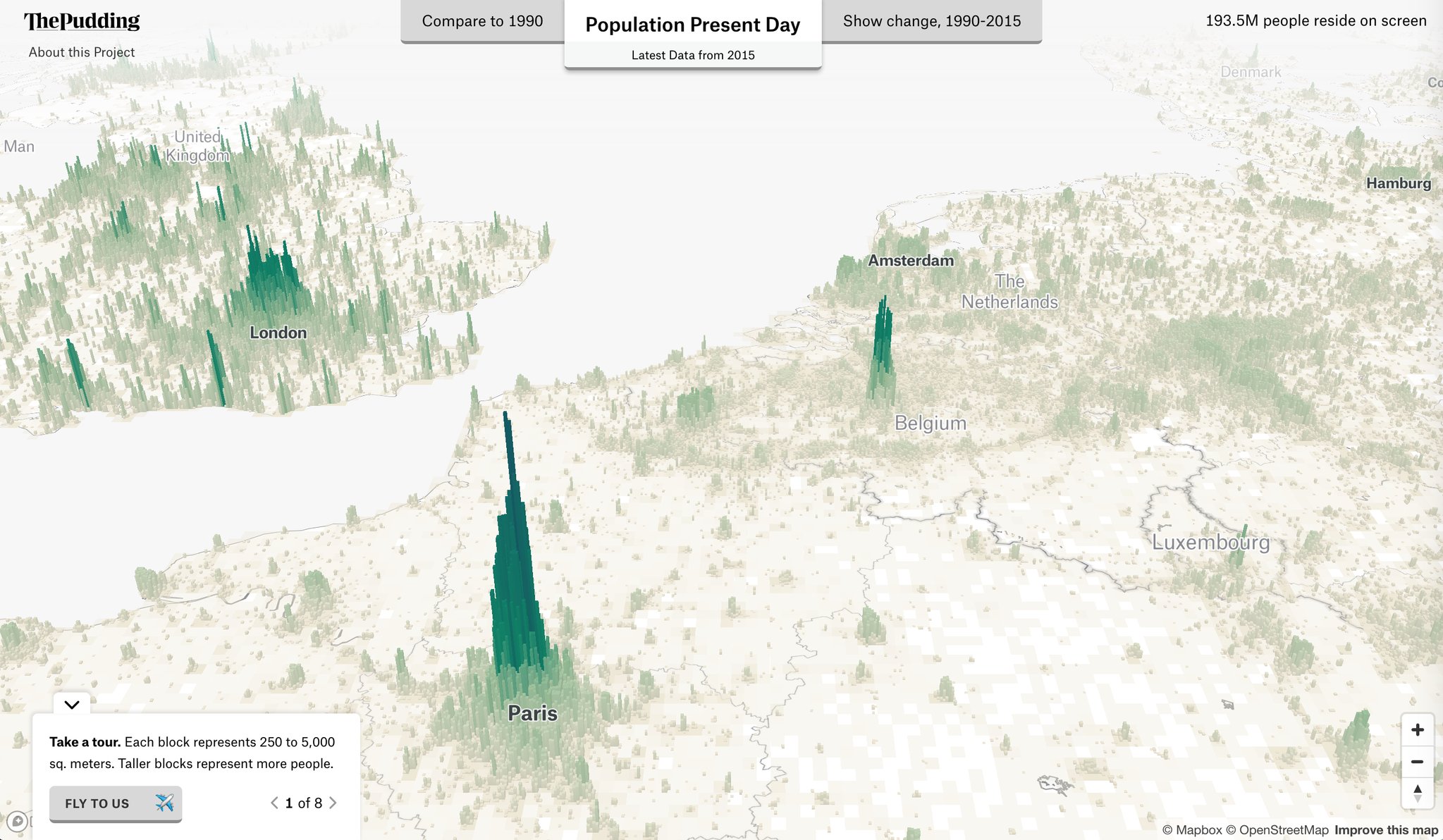
Here is a lovely interactive population map that I found recently on Twitter (h/t @maartenzam):
Principles of Algorithmic Problem Solving, by Johan Sannemo, with HN thread, provides a nice introduction to desigining various algorithms, ranging from brute-force methods to dynamic programming, combinatorics or number theory. It uses C++ like the Competitive Programmer’s Handbook that I reviewed earlier.
I read a few interesting blog posts recently:
-
The Story of Emacs Lisp (Irreal), with follow up posts, provides an interesting account of Emacs history.
-
How to automate common tasks (Stata blog), or how to deal with scripting, do-file and ado programming in Stata.
-
Practical Peer Review (Three-Toed Sloth). What else to say?
This is the importance of grasping, or really of making part of one’s academic self, two truths about peer review.
- The quality of peer review is generally abysmal.
- Peer reviewers are better readers of your work than almost anyone else.
-
Statistically Efficient Ways to Quantify Added Predictive Value of New Measurements (Frank Harrell), a really thoughful discussion of predictive modeling with discrete outcomes.
I just learned about nextflow which enables scalable and reproducible scientific workflows using software containers (actually, Docker and Singularity). What is interesting is that it relies on the idea of Un*x interoperability between processes via pipes (something that we also found in Elixir or R, or even Python). While I have a hard time using pipes when writing R scripts, I can imagine the benefit of this approach in various settings, especially data processing workflow.
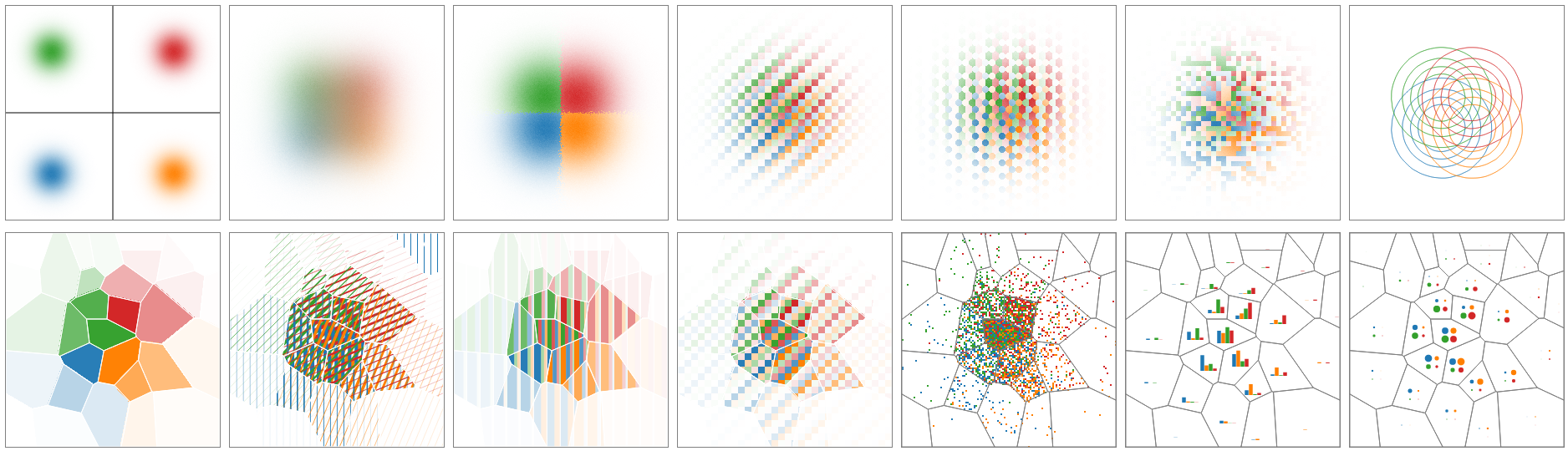
A new Vega-based implementation of density maps, this time for multiclass problems, is available on Github. The first time I saw it, this reminded me of Hadley Wickham’s work on Embedded Plots (or maybe, Glyph Maps).
As I always loved 3D moving geometrical objects–and I regularly check plenty of them on Twitter, here is one to end this review:
— dave (@beesandbombs) October 2, 2018