Workflow for statistical data analysis
Few days ago, I came across Oliver Kirchkamp’s Workflow of statistical data analysis which provides essential tips and guidelines for managing not only data but the whole analysis flow (from getting raw data to publishing papers).
For R users
This is a very comprehensive textbook, with illustrations in R. I already dropped some words two years ago in How to efficiently manage a statistical analysis project. People with little knowledge of R can skip chapter 2 and go directly to chapter 3 which goes to the heart of the problem: How to create and manage a statistical project in R?
In few words:
- Don’t only rely on copy/paste for executing commands; write one or several R scripts and
sourcethem from a master file; - Use relative not absolute paths;
- Prefer (possibly nested) functions to series of commands; they take arguments and have returned values (hence, we can control potential side-effects);
- Take care of random number generation (
set.seed(), etc.); - Make use of comments extensively (at the beginning of each function, anywhere in your scripts to document non obvious steps or indicate brief history of earlier attempts, for example;
- Choose variable names with care (‘short but not too short’).
Chapter 5 is about data manipulation: subsetting (subset()–I like this function a lot), merging (merge()) and reshaping (stats::reshape()–I prefer the reshape2 package). I’m currently writing a textbook on data manipulation and visualization with R and I have planned to include a dedicated chapter on that topic. However, it is likely it will rely on base functions as well as the plyr and Hmisc packages.
I noticed that the author seems to make extensive use of the memisc package, for codebook, variable labeling and description (e.g., p. 57), importing Stata dataset. Another interesting point is made p. 56 about data signature using tools::md5sum(). Chapter 7 and 8 are about Weaving/Tangling R code (with a brief indication of how to write a minimal Makefile) and version control (SVN). Again, discussion about VC engines is kept to the bare essential, but this is good to point to that possibility. RStudio now has full support for git and Subversion.
For Stata users
Another great book I happened to order recently is dedicated to statistical analysis with Stata: J. Scott Long, The workflow of data analysis using Stata. Stata Press, 2009.
However, after having skimmed over a few random pages I feel it would apply equally to R or other software package. There is a companion package that can be found by issuing
. findit workflow
at Stata prompt. It targets Stata 9 and 10, but it will work with Stata 12. It essentially consists in two separate packages wf*-part1 and wf*-part2, and a set of help files, wf-help.
The first two packages are dta and do files that are used throughout the book (datasets and Stata commands). They all goes in your home directory by default. As a matter of fact, everything is labelled as wf* such that it is easy to move them elsewhere on your hard drive. That is about 160 files in total:
$ ls wf* | wc -l
157
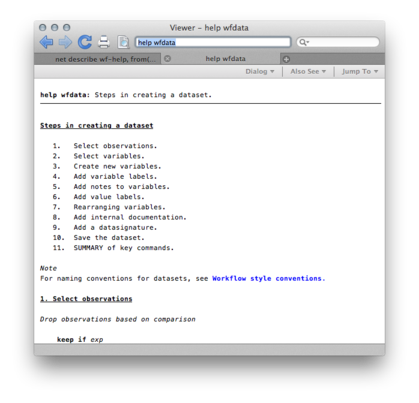
About wf-help, here is a snapshot of what’s going to be installed in your personal ado folder (left panel below). After that, you will be able to type query help for wfdata, and get the screen reproduced below (right):
I have to read the book now, and I will probably update this post with a more detailed summary.