Latest micro-posts
You can also also view the full archives of micro-posts. Longer blog posts are available in the Articles section.
Join Hands by Siouxsie and the Banshees after Meds by Placebo. I suppose this is okay, isn’t it?
wander.md: the markdown editor that is yours. I already
like this native macOS app. It supports tags and it works with folder (like
Obsidian) or single file (like Typora). I’m waiting for $\LaTeX$ and Pandoc
exporting backend support. For mmore information, see this discussion on
Reddit.
#apple
I’ve just been listening to Muse’s album Absolution XX. And I’ve realised that this micro-blog is already eight years old, now full of 4370 posts. Time flies – it’s mad!
/me is listening to “A Noiseless Noise” by PJ Harvey
After one month without internet access at home, my MacBook got fully
synchronized (I guess) and I can run software update as usual. #apple
The twitter stuff got me thinking that, while I was never a prolific poster, I barely posted at all over the last 4–5 years. Unless you are big and have a following, what was the point other than publicly tweeting friends, whom I mostly communicate now through a private Discord server. Social media has mostly become about consumption, and not discussion or sharing. That is unfortunate. — Internet presence
This micro-blog is the raison d’être of keeping the site live and to do without social networks of any kind.
macOS catalina and music. And I learned about yet another music player for macOS. That being said, I long have had mixed feelings about Apple Music. I was used to iTunes and its way of managing multiple media sources. Now I came to appreciate the split between Music and TV, but the management of album art sucks more often than not (look at the screenshot below, it’s been months that artist gravatars come up randomly, and it’s far from being completed right now; moreover, even if all my files are correctly tagged with lyrincs and image art embedded within the MP3, Apple Music sometimes doesn’t display album art in the mini display), and play counts are synchronized with a random delay between my iPhone (via Apple Music matching process) and my MacBook. Contrary to the author I was not so much concerned by the move from iTunes to Music since I crafted my digital library afterwards, and I already lost my ratings and play counts multiple times ;-)
/me is listening to “Over And Over” by Camper Van Beethoven
TIL that BBEdit has a Vi mode.
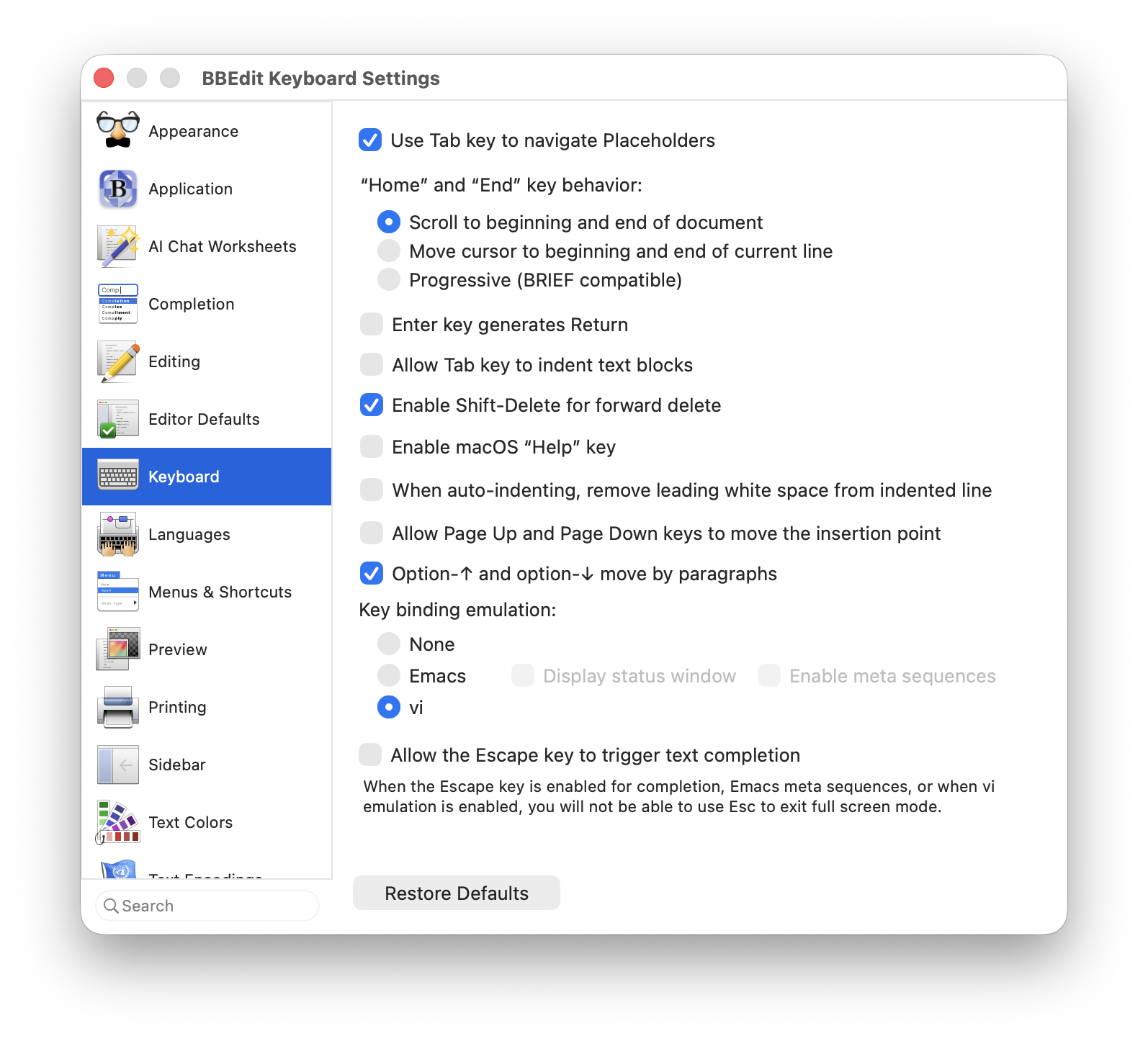
TIL we can use Ctrl + Enter to display macOS contextual menu. #apple