On va s'intéresser dans cette première partie à l'importation d'un jeu de données déjà disponible dans R, et à passer en revue les commandes de base permettant de : recoder les variables qualitatives, annoter les variables, afficher les principaux descripteurs numériques des variables quantitatives et qualitatives, et étudier la distribution de ces variables.
Dans un premier temps, on importe les données birthwt, qui sont disponibles dans le package MASS (taper data(package="MASS" pour avoir une idée de l'ensemble des jeux de données disponible dans ce package).
rm(list = ls())
data(birthwt, package = "MASS")
ls()## [1] "birthwt"On voit que dans l'espace de travail on a maintenant accès aux données qui sont stockées dans un tableau (data.frame) nommé birthwt. Le nom des variables contenues dans le tableau de données peut être obtenu à l'aide de la commande names.
names(birthwt)## [1] "low" "age" "lwt" "race" "smoke" "ptl" "ht" "ui" "ftv"
## [10] "bwt"Il est important de toujours vérifier le mode de représentation des données, c'est-à-dire comment R traite les variables importées (quantitatives vs. qualitatives).
str(birthwt)## 'data.frame': 189 obs. of 10 variables:
## $ low : int 0 0 0 0 0 0 0 0 0 0 ...
## $ age : int 19 33 20 21 18 21 22 17 29 26 ...
## $ lwt : int 182 155 105 108 107 124 118 103 123 113 ...
## $ race : int 2 3 1 1 1 3 1 3 1 1 ...
## $ smoke: int 0 0 1 1 1 0 0 0 1 1 ...
## $ ptl : int 0 0 0 0 0 0 0 0 0 0 ...
## $ ht : int 0 0 0 0 0 0 0 0 0 0 ...
## $ ui : int 1 0 0 1 1 0 0 0 0 0 ...
## $ ftv : int 0 3 1 2 0 0 1 1 1 0 ...
## $ bwt : int 2523 2551 2557 2594 2600 2622 2637 2637 2663 2665 ...Si l'on se réfère à l'aide en ligne, help(birthwt, package="MASS"), on voit clairement que les données ne sont pas stockées au bon format : certaines variables qui devraient être purement qualitative (oui/non) sont codées en 0/1 ; dans tous les cas, les étiquettes des modalités des variables ne sont strictement pas informatives.
yesno <- c("No", "Yes")
ethn <- c("White", "Black", "Other")
birthwt <- within(birthwt, {
low <- factor(low, labels = yesno)
race <- factor(race, labels = ethn)
smoke <- factor(smoke, labels = yesno)
ui <- factor(ui, labels = yesno)
ht <- factor(ht, labels = yesno)
})
summary(birthwt)## low age lwt race smoke ptl
## No :130 Min. :14.0 Min. : 80 White:96 No :115 Min. :0.000
## Yes: 59 1st Qu.:19.0 1st Qu.:110 Black:26 Yes: 74 1st Qu.:0.000
## Median :23.0 Median :121 Other:67 Median :0.000
## Mean :23.2 Mean :130 Mean :0.196
## 3rd Qu.:26.0 3rd Qu.:140 3rd Qu.:0.000
## Max. :45.0 Max. :250 Max. :3.000
## ht ui ftv bwt
## No :177 No :161 Min. :0.000 Min. : 709
## Yes: 12 Yes: 28 1st Qu.:0.000 1st Qu.:2414
## Median :0.000 Median :2977
## Mean :0.794 Mean :2945
## 3rd Qu.:1.000 3rd Qu.:3487
## Max. :6.000 Max. :4990La commande within permet d'éviter de devoir préfixer systématiquement le nom des variables par le nom du tableau de données (data.frame, ici birthwt). On remarquera également que le poids de la mère (lwt) est exprimé en livres alors que le poids des bébés est en grammes.
birthwt$lwt <- birthwt$lwt/2.2La commande ci-dessus remplace toutes les valeurs de lwt par le résultat de leur division par un facteur 2.2 (pounds -> kg). On aurait pu créer une variable auxiliaire et l'ajouter au tableau de données comme ceci :
birthwt$lwt2 <- birthwt$lwt/2.2À présent, il est plus facile d'interpréter n'importe quel résumé numérique ou de se référer à certaines des valeurs prises par les variables. On peut faire mieux et ajouter des étiquettes décrivant les variables (pas leurs modalités), ainsi que les unités de mesure. Pour cela, il est nécessaire de "charger" un package externe, Hmisc (Alzola & Harrell, 2006), qui contient les commandes nécessaires, label et units.
library(Hmisc)
birthwt <- within(birthwt, {
label(low) <- "Indicateur de sous-poids (< 2.5 kg)"
label(age) <- "Age de la mère"
units(age) <- "années"
label(lwt) <- "Poids de la mère"
units(lwt) <- "kg"
label(race) <- "Ethnicité de la mère"
label(smoke) <- "Mère fumant durant la grossesse"
label(ptl) <- "Nombre de naissances avant-terme antérieures"
label(ht) <- "Antécédent d'hypertension"
label(ui) <- "Présence de douleurs intra-utérines"
label(ftv) <- "Nombre de visites chez le médecin durant le 1er trimestre de grossesse"
label(bwt) <- "Poids du bébé à la naissance"
units(bwt) <- "g"
})Ces annotations supplémentaires n'affectent en rien le fonctionnement habituel des commandes R. Par contre, on pourra y avoir accès grâce à des commandes spécifiques du package Hmisc, par exemple:
describe(birthwt)En pratique, cette comamnde permet également d'inspecter chaque variable (idée du "codebook"), et complète l'usage de str et summary. Voici un aperçu de ce que retourne cette commande :
birthwt
10 Variables 189 Observations
--------------------------------------------------------------------------------
low : Indicateur de sous-poids (< 2.5 kg)
n missing unique
189 0 2
No (130, 69%), Yes (59, 31%)
--------------------------------------------------------------------------------
age : Age de la mère [années]
n missing unique Mean .05 .10 .25 .50 .75 .90
189 0 24 23.24 16 17 19 23 26 31
.95
32
lowest : 14 15 16 17 18, highest: 33 34 35 36 45
--------------------------------------------------------------------------------
lwt : Poids de la mère [kg]
n missing unique Mean .05 .10 .25 .50 .75 .90
189 0 75 59.01 42.91 45.27 50.00 55.00 63.64 77.27
.95
85.55
lowest : 36.36 38.64 40.45 40.91 41.36
highest: 97.73 104.09 106.82 109.55 113.64 Cette commande, describe, peut être utilisée sur des variables directement.
describe(birthwt$race)## birthwt$race : Ethnicité de la mère
## n missing unique
## 189 0 3
##
## White (96, 51%), Black (26, 14%), Other (67, 35%)describe(birthwt$lwt, digits = 3)## birthwt$lwt : Poids de la mère [kg]
## n missing unique Mean .05 .10 .25 .50 .75 .90
## 189 0 75 59 42.9 45.3 50.0 55.0 63.6 77.3
## .95
## 85.5
##
## lowest : 36.4 38.6 40.5 40.9 41.4, highest: 97.7 104.1 106.8 109.5 113.6L'option digits=3 permet de limiter l'affichage des nombres à 3 chiffres significatifs.
La commande summary fournit déjà l'essentiel des informations. Par exemple,
summary(birthwt$age)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 14.0 19.0 23.0 23.2 26.0 45.0On peut obtenir séparemment ces informations comme suit :
mean(birthwt$age)## [1] 23.24quantile(birthwt$age, prob = c(0, 0.25, 0.5, 0.75, 1))## Age de la mère [années]
## 0% 25% 50% 75% 100%
## 14 19 23 26 45range(birthwt$age)## [1] 14 45L'étendue s'obtient comme la différence entre la valeur maximale et la valeur minimale observée pour cette variable, soit
diff(range(birthwt$age))## [1] 31Concernant les variables qualitatives, si elles sont bien représenétes comme des factor sous R, summary fournit un résultat identique à table, c'est-à-dire un tableau d'effectifs. Par exemple, avec la variable race on a :
table(birthwt$race)##
## White Black Other
## 96 26 67Pour obtenir des fréquences relatives (ou des proportions), on peut diviser les valeurs obtenues par la taille totale de l'échantillon (n = 189), ou utiliser la commande prop.table.
prop.table(table(birthwt$race))##
## White Black Other
## 0.5079 0.1376 0.3545Attention toutefois, en présence de valeurs manquantes une commande telle que table(birthwt$race)/length(birthwt$race) renverrait les fréquences rapportées à l'effectif total, et non les fréquences sur données observées.
Dans le même ordre d'idées, on peut obtenir un tableau des effectifs cumulés en combinant table avec la commande cumsum :
cumsum(table(birthwt$race))## White Black Other
## 96 122 189Les commandes utilisées proviennent du package lattice (Murrell, 2005; Sarkar, 2008). Le package latticeExtra fournit un ensemble de fonctionnalités supplémentaires.
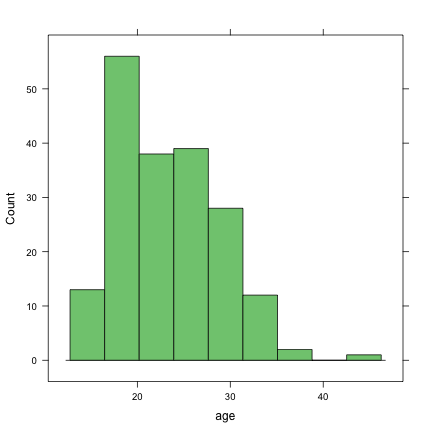
Pour visualiser la distribution de l'âge des mères, on peut utiliser un histogramme.
library(lattice)
histogram(birthwt$age, type = "count")Cette approche est tout à fait correcte, mais on peut exploiter directement la structure de données ou data.frame.
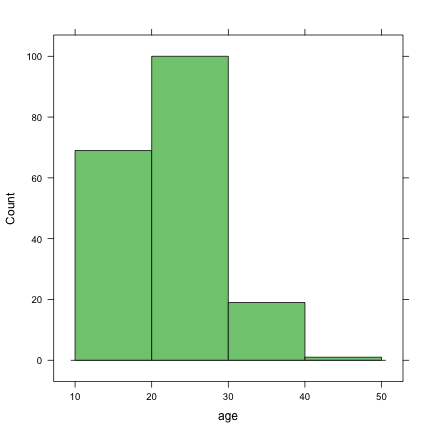
histogram(~age, data = birthwt, type = "count")On notera une petite différence : à partir du moment où utilise l'option data=, il est nécessaire d'utiliser l'opérateur ~ pour spécifier la relation entre les variables sélectionnées : ici, il s'agit d'une relation unaire, d'où la notation ~ age pour caractériser la distribution univariée des âges. L'option type="count" permet de changer l'affichage par défaut (fréquences) en effectifs. Il existe bien entendu de nombreux paramètres permettant de modifier l'aspect général de ce genre de graphique. Concernant le choix des classes d'intervalle, bien que R détermine généralement de manière optimale le nombre et la taille des intervalles, on peut les modifier à l'aide de l'option break=. Supposons, par exemple, que l'on souhaite définir 4 classes incluant (ou recouvrant) les valeurs minimales de l'âge. Une façon de procéder est d'utiliser la commande pretty comme ceci :
histogram(~age, data = birthwt, type = "count", breaks = pretty(range(birthwt$age),
4))
Enfin, on peut tout à fait changer les annotations textuelles (axes horizontaux et verticaux), voire la couleur des barres.
histogram(~age, data = birthwt, type = "count", xlab = "Âge de la mère", ylab = "Effectif")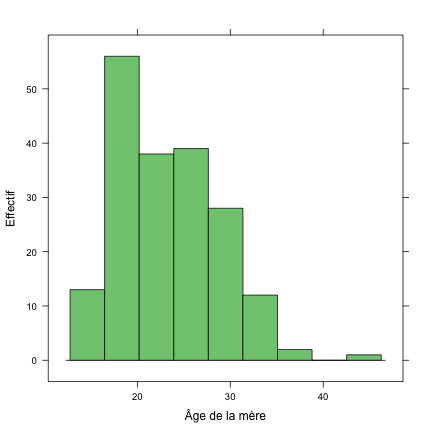
L'option main= permettrait d'ajouter un titre au graphique.
Concernant les variables qualitatives, telles que le fait de fumer durant la grossesse (smoke), on peut représenter graphiquement le tableau des effectifs sous forme d'un diagramme en barres.
barchart(table(birthwt$smoke), xlab = "Effectifs")
L'option horizontal=FALSE permet d'afficher les barres verticalement plutôt qu'horizontalement. Une approche équivalente consiste à utiliser des diagrammes de type "dotplot" de Cleveland (Cleveland, 1985). Par exemple, pour le facteur relatif à l'ethnicité de la mère,
dotplot(prop.table(table(birthwt$race)) * 100, xlab = "Proportion", aspect = 0.6)
Comme on peut le voir, il n'est pas difficile de transformer les fréquences relatives retournées par prop.table sous forme de pourcentages.
Bien que cela sorte du cadre de la description purement univariée, on notera qu'il est assez facile d'afficher la distribution de l'âge des mères en fonction de certain critères. Par exemple, pour afficher les âges des mères selon que les bébés sont considérés comme ayant un poids inférieur à la norme ou non, on peut utiliser la commande suivante :
histogram(~age | low, data = birthwt, xlab = "Age des mères", type = "count", ylab = "Effectifs")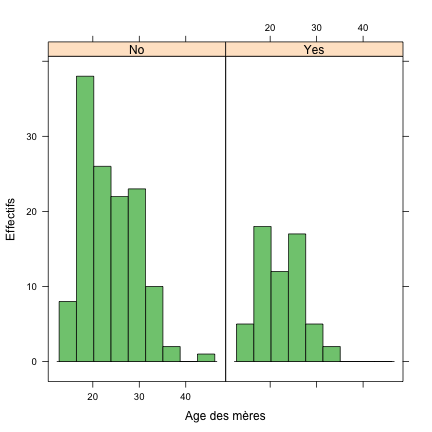
L'opérateur | permet le conditionnement d'une variable, ici age, sur une autre, ici low. En d'autres termes, l'instruction ci-dessus revient à considérer les valeurs de la variable age pour chacun des niveaux du facteur low.
Jusqu'à présent on s'est contenté d'importer un fichier de données, de recoder les variables et de décrire les principaux indicateurs de tendance centrale et de dispersion, ainsi que de visualiser les distributions de chaque variable. Dans cette partie, on va s'intéresser à l'inspection des valeurs individuelles contenues dans une variable (principe de l'adressage des valeurs d'une variable).
L'élément fondamental du langage R est le vecteur. Dans la plupart des cas, on ne fera pas de distinction de langage entre "vecteur" et "variable". Le 5ème élément du vecteur age, ou encore la 5ème observation de la variable age, s'obtient ainsi :
birthwt$age[5]## Age de la mère [années]
## [1] 18On voit que les crochets sont utilisés pour adresser des éléments spécifiques de age, sachant que le premier élément porte l'index 1 (et non 0 comme dans certains autres langages). Dans l'exemple suivant, on demande le premier et le dernier élément, puis les 5 premiers éléments.
birthwt$age[c(1, 189)]## Age de la mère [années]
## [1] 19 21birthwt$age[1:5]## Age de la mère [années]
## [1] 19 33 20 21 18On peut également obtenir les éléments d'un vecteur à partir des informations contenues dans une autre variable (principe du dictionnaire).
birthwt$age[birthwt$low == "Yes"]## Age de la mère [années]
## [1] 28 29 34 25 25 27 23 24 24 21 32 19 25 16 25 20 21 24 21 20 25 19 19 26 24
## [26] 17 20 22 27 20 17 25 20 18 18 20 21 26 31 15 23 20 24 15 23 30 22 17 23 17
## [51] 26 20 26 14 28 14 23 17 21Les exemples ci-dessus permettent de travailler au niveau des observations et de répondre à des questions du type : quelles sont les valeurs d'une variable dont les observations remplissent certaines conditions (position dans le vecteur ou valeurs prises dans une autre variable).
On peut tout à fait procéder de même avec les variables, et restreindre le tableau de données à une sélection de celles-ci. Par exemple, pour n'afficher que les 6 premières observations pour les variables age et low, on peut utiliser la commande suivante :
birthwt[1:6, c("low", "age")]## low age
## 85 No 19
## 86 No 33
## 87 No 20
## 88 No 21
## 89 No 18
## 91 No 21On voit ici que pour adresser des éléments d'un tableau, et non plus d'un vecteur, on utilise toujours des crochets mais cette fois-ci en indiquant les lignes et les colonnes, séparées par une virgule. Ainsi, birthwt[3,6] designe la valeur enregistrée pour le 3ème individu à la variable ptl (que l'on peut retrouver avec names(birthwt)[6]). Elle est équivalente à birthwt[3,"ptl"].
Il est possible de combiner ces deux approches (filtrage des observations et filtrage des variables) à l'aide de la commande subset. La commande birthwt[1:6,c("low","age")] se traduit ainsi par :
head(subset(birthwt, select = c("low", "age")))## low age
## 85 No 19
## 86 No 33
## 87 No 20
## 88 No 21
## 89 No 18
## 91 No 21ou subset(birthwt, select=c("low","age"))[1:6,], mais on peut réaliser des combinaisons plus complexes telles que
subset(birthwt, subset = smoke == "Yes" & ht == "Yes", select = c("low", "age"))## low age
## 187 No 19
## 197 No 19
## 11 Yes 34
## 20 Yes 21
## 84 Yes 21Dans ce cas de figure, on a effectué un double filtrage : on ne retient que les observations pour lesquelles smoke=="Yes" et (&) ht=="Yes" (soit les mères fumeuses ayant des antécédents d'hypertension), pour les seules variables low et age.
Ce genre de restriction peut tout à fait être utilisé dans les représentations graphiques, grâce à l'option subset=. Dans l'exemple suivant, on affiche la distribution de l'âge des mères pour lesquelles le poids de l'enfant peut être considéré comme dans les normes.
histogram(~age, data = birthwt, xlab = "Age des mères", type = "count", subset = low ==
"No")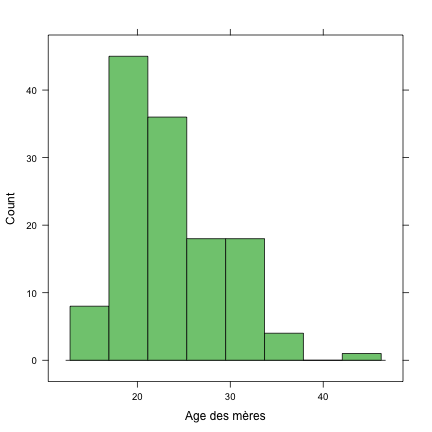
Alzola, C., & Harrell, F. (2006). An Introduction to S and The Hmisc and Design Libraries.
Cleveland, W. S. (1985). The Elements of Graphing Data. Monterey, CA: Wadsworth.
Murrell, P. (2005). R Graphics. Chapman & Hall/CRC.
Sarkar, D. (2008). Lattice, Multivariate Data Visualization with R. Springer.