Latest micro-posts
You can also also view the full archives of micro-posts. Longer blog posts are available in the Articles section.
As I am using Postgresql a lot these days, I thought I would import a large CSV
file (1 Go) to see if I can play with in-database tools from dplyr & Co. I will
probably need this for work so it’s worth the effort. I started with a Stata
file that I read using haven, and I converted it to a CSV using
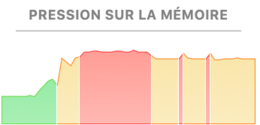
data.table::fwrite. This already eated up all my RAM. Now, I’m using csvkit to
import the CSV file into a Postgresql local database. Well, it says a lot about
the process:
I guess I just found another org-powered user! #emacs
Just added to my Papers list: Mean and median bias reduction in generalized
linear models. See also the brglm2 R package. #rstats
I haven’t written a single line of Latex in a long time, but it looks like we now get Font Awesome for free in our TeX distribution. (via @kaz_yos)
It’s astonishing how much work has been done regarding working with database
using R. We now have dbplot and modeldb (not to be confused with this one). (via
@theotheredgar) #rstats
syn uses OS X’s natural language processing tools to tokenize and highlight
text. Nice utility to add to my writing stack. It is used by Emacs
wordsmith-mode. #emacs
Okay, so it looks like we started with season 2 of The Expanse instead of season 1. Great! That may well explain why we didn’t understand anything during the first episodes.
Prompted by a recent Twitter question, I was about to benchmark some R packages
to process large files. However, there already seems to be a very nice post
about this: Working with pretty big data in R. #rstats