ArXiving on August 2022
Here are a few papers that I read over the past weeks, in the CS and Stat category as usual.
Inverse Probability Weighting: the Missing Link between Survey Sampling and Evidence Estimation (https://arxiv.org/abs/2204.14121)
Inverse probability weighting is used in survey and epidemiological analysis. I only used this technique once, and it was in quick comparison with propensity score analysis, where the key idea was in both case to achieve balance between treated and control subjects in order to reduce confounding. See Chan, K. C. G., et al. Globally efficient non-parametric inference of average treatment effects by empirical balancing calibration weighting (Journal of the Royal Statistical Society: Series B 78(3), 2016) for recent work. In this article, the authors discuss the use of binning and smoothing, or, as an alternative, hierarchical modeling. Their conclusions are that those Bayesian estimators perform better (i.e., they have lower mean squared errors) compared to simple IPW estimators.
Redefining Populations of Inference for Generalizations from Small Studies (https://arxiv.org/abs/2204.14156)
This article deals with the inference population that small sample studies usually focus on, and how it can be improved to foster valid generalizations (of the population average treatment effect, or PATE). This is based on the results from a cluster randomized trials in educational assessment. The two approaches considered here are coined “quantitatively optimal” and “policy-relevant” approaches. In the former case, the analysis relies on propensity scoring with varying cutoffs or the distributions of covariates. In the latter case, the idea is to identify subgroups that may benefit from the intervention. To improve imprecision, bot approaches can be undertaken, while for bias reduction only the quantitatively optimal approaches seem relevant.
Practical considerations for specifying a super learner (https://arxiv.org/abs/2204.06139)
Along with classical parametric regression models or ensemble methods in machine learning, the super learner algorithm allows to learn a prediction function without needing to set on a fixed modeling approach: as an entire pre-specified and adaptive strategy, it allow the modeler to consider several predictive models at once. Here’s the big picture:
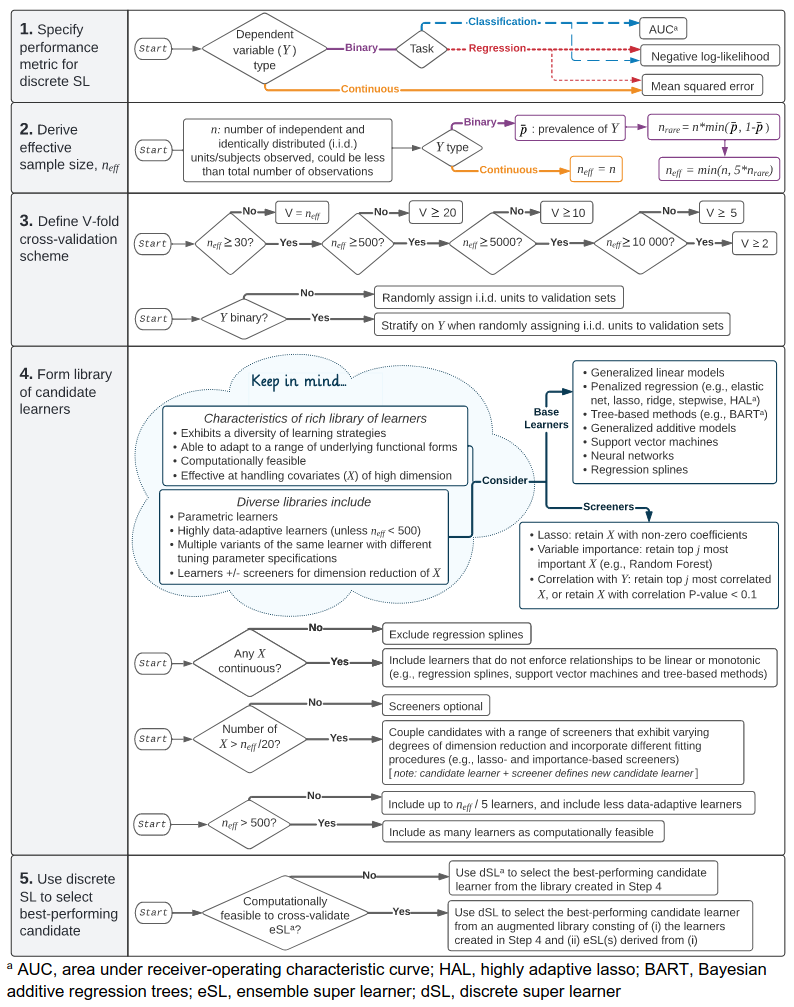
For the practictioner, the core decisions are to (1) specify the performance metric for the discrete super learner, (2) derive the effective sample size, (3) define the V-fold cross-validation scheme, (4) form library of candidate learners, and (5) to use discrete super learner to select the candidate with the best cross-validated predictive performance.
PaC-trees: Supporting Parallel and Compressed Purely-Functional Collections (https://arxiv.org/abs/2204.06077)
This paper presents PaC-trees, a purely-functional data structure supporting functional interfaces for sets, maps, and sequences that provides a significant reduction in space over existing approaches. A PaC-tree is a balanced binary search tree which blocks the leaves and compresses the blocks using arrays. We provide novel techniques for compressing and uncompressing the blocks which yield practical parallel functional algorithms for a broad set of operations on PaC-trees such as union, intersection, filter, reduction, and range queries which are both theoretically and practically efficient.
See also Parallel Augmented Maps.
Correction of overfitting bias in regression models (https://arxiv.org/abs/2204.05827)
This article describes solutions to correct for the biais arising from overfitting datastes where $p/n < 1$. Besides regularization techniques, the asymptotic characteristic function of the ML estimators can be used to estimate the overfitting bias using only a small set of non-linear equations. The maths are dense, and I will probably need to reread the hard part.
♪ New Order • Video 5 8 6