Data science at the command line
Here is a short review of Data Science at the Command Line, by Jeroen Janssens (O’Reilly, 2014).
First of all, I must say that I really enjoyed reading this book, although I had not much time to spend playing with the various examples. However, when you have a bit of knowledge of the command-line, sed/awk, GNU coreutils, and UNIX philosophy, it’s not hard to envision the power of a command-line approach to data analysis. I often use a lot of small sed or awk one-liner to perform basic operations on this blog. John Chambers advocated long ago that many operations on text files can be handled with programs like sed, awk, or Perl.1 Other than tabular CSV files, many other data formats (JSON, XML, etc.) can easily be handled by command-line utilities, see Coursera’s Data Science Toolbox (Chapter 3 on “Getting and Cleaning Data”), or Paul Murrell’s on-line textbook on data technologies.2 Sometimes, I feel like I could take advantage of R’s powerful capabilities to perform data preprocessing and data cleansing, but obviously this book makes strong arguments to perform such things directly from your Bash or zsh prompt.
The take away messages are simple: (1) use small programs that do one thing well and handle STDIN/STDOUT as expected; (2) don’t neglect old GNU software–they’ve been developed twenty or thirty years ago and they work always as good as they used to work in the past; (3) take a look at modern tools like csvkit; (4) think of UNIX pipes (|) as a way of organizing your data workflow; (5) be creative: there’s more than one way to do it.
Because I have nothing to do on this Sunday, here is a simple illustration of using different programs to perform a very basic operation: converting an SPSS file to CSV format. Why this matters? Well, currently SPSS format is not easy to parse and, e.g., Stata does not even provide a built-in reader. There’s already a Perl program that allows to process SPSS files, but if you already have R installed on your computer, why not use it directly? So, let’s say you just want to write an SPSS reader. Let’s try this first, assuming your SPSS file is test.sav:
$ Rscript -e "foreign::read.spss('test.sav', to.data.frame = TRUE)" > test.dat
Now the file test.dat looks like this:
$ head -n 3 test.dat
ANY BORED CRITICS PEERS WRITERS DIRECTOR CAST
1 NO NO NO NO YES YES YES
2 YES YES NO YES YES YES YES
To convert this file to a suitable CSV format, we could do something like:
$ cat test.dat | \
tr -s '[:blank:]' ',' | \
cut -d "," -f 2-8 | \
tr '[:upper:]' '[:lower:]' > test.csv
The first command makes use of R’s foreign package to load the SPSS file and convert it to a data frame, which is a simple rectangular array of records separated by TAB. One minor annoyance with the generated test.dat file is that it includes row names (as consecutive integers in the first field). Furthermore, it is a good idea to convert spaces or TAB by comma to get a proper CSV file. We then use tr for that purpose1, and cut to remove the first column. Finally, we again call tr to convert all records to lower case. Of course, this is just for the purpose of illustrating the use of tr, cut and UNIX pipe. Otherwise, it is really much simpler to wrap the R command into write.csv(..., file = 'test.csv', row.names = FALSE).
Bioinformatics is also a domain where large amount of data are generated using various technologies (SNPs, short read, etc.) and for which efficient solutions exist (e.g., samtools). Although not mentioned in the book, the available examples already provide a good idea of what can be done within the command-line and how tools like csvkit or GNU coreutils could be used to process or filter such kind of data.
Other command-line toolbox are worth mentioning, though:
- waffles is both an API and a series of shell program to perform exploratory data analysis and statistical modeling (mostly inspired from the Machine Learning community).
- Gary Perlman’s |stat is an old package to perform common statistical operations (numerical summaries, ANOVA, regression) directly from the command-line.
- datamash, which offers minimal support for descriptive statistics and data aggregation (it’s still in early infancy at the time of this writing).
- Ben Klemens’ apophenia also provides an API and small shell scripts to perform most common statistical operations based on plain text files or SQLite database.
There are plenty of open-source shell scripts or small programs that do only one thing, but in a way that their output can be post-processed by other tools. I can think of formd, which convert inline to referenced hyperlinks in Markdown documents, or Kieran Healy’s Pandoc templates from which I create the following shell script, mdpretty, which I also use as a custom processor in Marked:
#!/usr/bin/env bash
pandoc -r markdown+simple_tables+table_captions+yaml_metadata_block -w html -s -S --template=/Users/chl/.pandoc/templates/html.template --css=/Users/chl/.pandoc/marked/kultiad-serif.css --filter pandoc-citeproc --csl=/Users/chl/.pandoc/csl/apsa.csl --bibliography=/Users/chl/Documents/bib/chl.bib
A simple way of using it is shown below.
$ < Dropbox/_posts/2014-10-12-data-science-command-line.md mdpretty > 1.html
It allows to convert a Markdown document to a pretty HTML page. That is, instead of the default preview version generated from Emacs (left), you get the HTML file on the right:
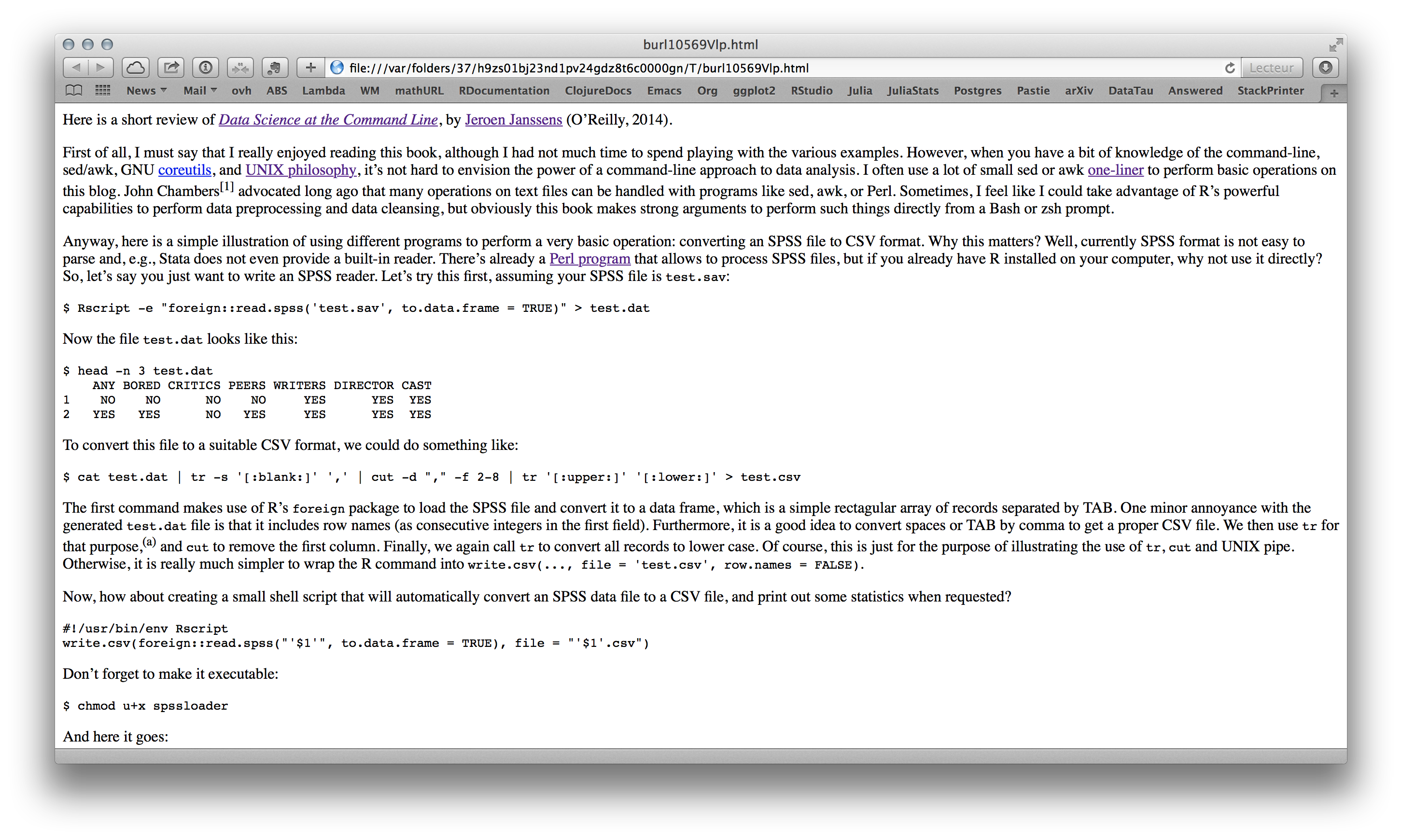
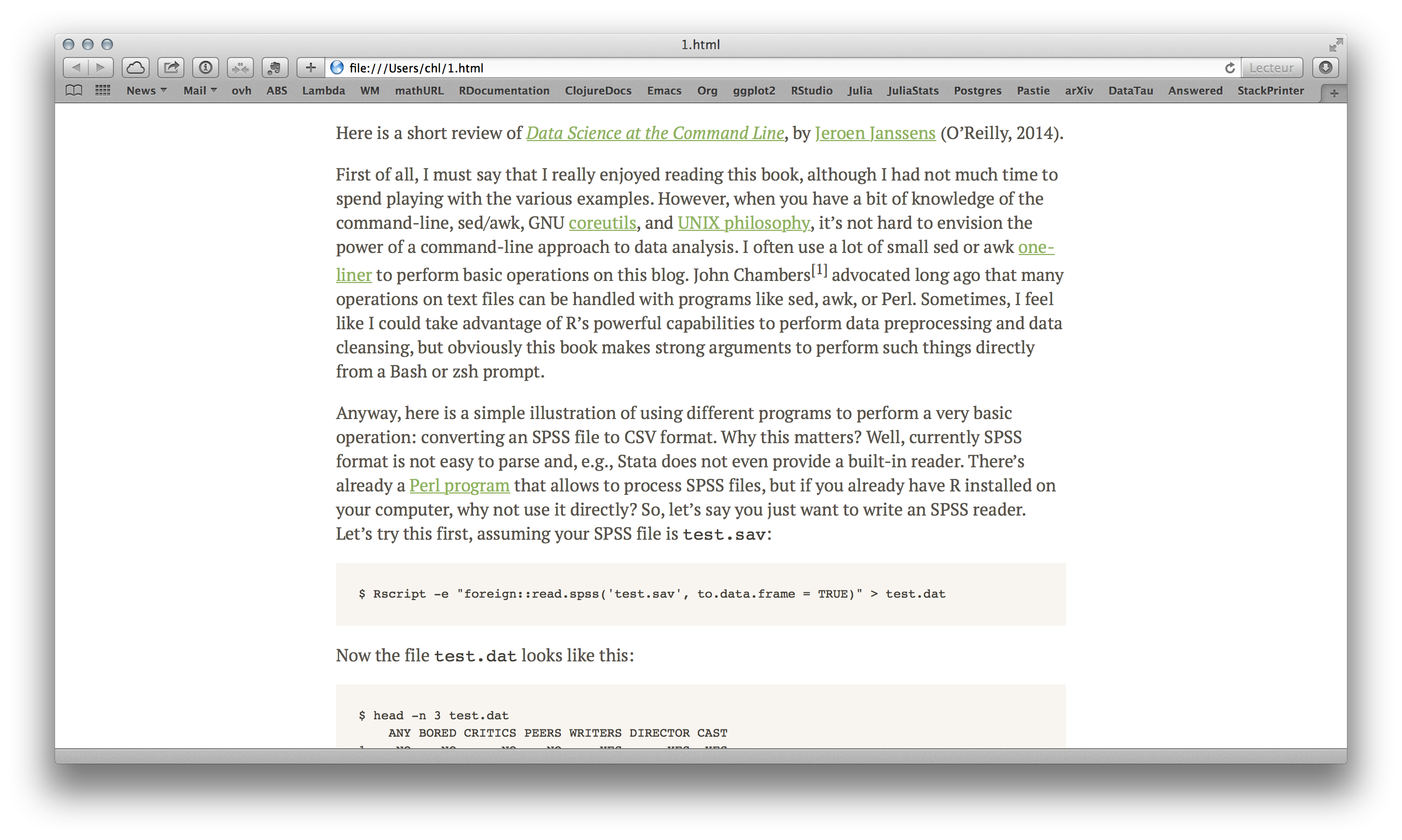
I will try to write a more concise review on O’Reilly website.
Chambers, J. (2008). Software for Data Analysis. Programming with R. Springer, 2008. ↩︎ ↩︎
Murrell, P. (2009). Introduction to Data Technologies. Chapman & Hall/CRC. ↩︎