Interacting with Weka from Jython
I discovered a lovely feature: You can use WEKA directly with Jython in a friendly interactive REPL.
Until now, I always preferred running Weka from the command line. For example, the following command fits Random Trees to the iris dataset:
$ weka weka.classifiers.trees.RandomTree -t iris.arff -i
Likewise, decision trees (J48 algorithm) might be run as follows:
$ weka weka.classifiers.trees.J48 -t iris.arff -i
J48 pruned tree
------------------
petalwidth <= 0.6: Iris-setosa (50.0)
petalwidth > 0.6
| petalwidth <= 1.7
| | petallength <= 4.9: Iris-versicolor (48.0/1.0)
| | petallength > 4.9
| | | petalwidth <= 1.5: Iris-virginica (3.0)
| | | petalwidth > 1.5: Iris-versicolor (3.0/1.0)
| petalwidth > 1.7: Iris-virginica (46.0/1.0)
Number of Leaves : 5
Size of the tree : 9
Time taken to build model: 0.08 seconds
Time taken to test model on training data: 0.01 seconds
The -i switch ensures results are displayed on the command line. Here, weka is just an alias that sits in my ~/.bash_aliases file:
alias weka='java -Xmx512m -classpath $CLASSPATH:weka.jar'
This approach is comparable to the use of the Simple CLI that is available in weka GUI, although the latter allows for classnames completion:
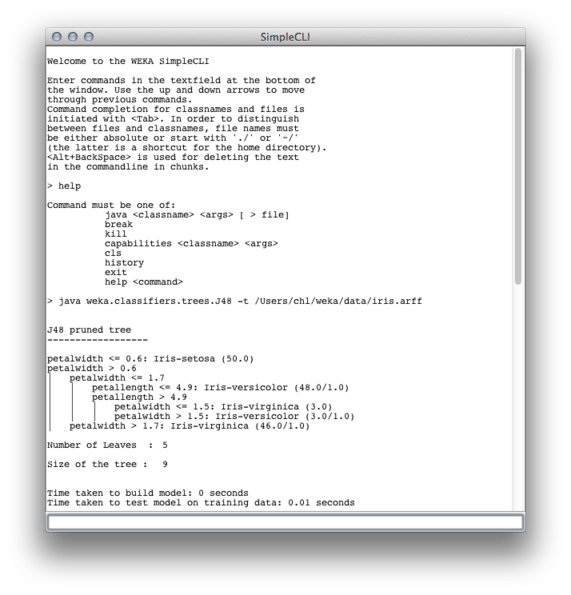
Online help is also a plus. E.g., at the Simple CLI prompt, you can get a list of all available option for this classifier: :
> java weka.classifiers.trees.J48 -h
Options specific to weka.classifiers.trees.J48:
-U
Use unpruned tree.
-O
Do not collapse tree.
-C <pruning confidence>
Set confidence threshold for pruning.
(default 0.25)
-M <minimum number of instances>
Set minimum number of instances per leaf.
(default 2)
-R
Use reduced error pruning.
-N <number of folds>
Set number of folds for reduced error
pruning. One fold is used as pruning set.
(default 3)
-B
Use binary splits only.
-S
Don't perform subtree raising.
-L
Do not clean up after the tree has been built.
-A
Laplace smoothing for predicted probabilities.
-J
Do not use MDL correction for info gain on numeric attributes.
-Q <seed>
Seed for random data shuffling (default 1).
From Jython, the same classifiers can be run as follows: (This code is roughly taken from WEKA Wiki.)
>>> import sys
>>> import java.io.FileReader as FileReader
>>> import weka.core.Instances as Instances
>>> import weka.classifiers.trees.J48 as J48
>>> file = FileReader("/Users/chl/weka/data/iris.arff")
>>> data = Instances(file)
>>> data.setClassIndex(data.numAttributes() - 1)
>>> j48 = J48()
>>> j48.buildClassifier(data)
>>> print j48
J48 pruned tree
------------------
petalwidth <= 0.6: Iris-setosa (50.0)
petalwidth > 0.6
| petalwidth <= 1.7
| | petallength <= 4.9: Iris-versicolor (48.0/1.0)
| | petallength > 4.9
| | | petalwidth <= 1.5: Iris-virginica (3.0)
| | | petalwidth > 1.5: Iris-versicolor (3.0/1.0)
| petalwidth > 1.7: Iris-virginica (46.0/1.0)
Number of Leaves : 5
Size of the tree : 9
>>> import weka.classifiers.trees.RandomTree as RT
>>> rt = RT()
>>> rt.buildClassifier(data)
>>> print rt
RandomTree
==========
petallength < 2.45 : Iris-setosa (50/0)
petallength >= 2.45
| petalwidth < 1.75
| | petallength < 4.95
| | | petalwidth < 1.65 : Iris-versicolor (47/0)
| | | petalwidth >= 1.65 : Iris-virginica (1/0)
| | petallength >= 4.95
| | | petalwidth < 1.55 : Iris-virginica (3/0)
| | | petalwidth >= 1.55
| | | | sepallength < 6.95 : Iris-versicolor (2/0)
| | | | sepallength >= 6.95 : Iris-virginica (1/0)
| petalwidth >= 1.75
| | petallength < 4.85
| | | sepallength < 5.95 : Iris-versicolor (1/0)
| | | sepallength >= 5.95 : Iris-virginica (2/0)
| | petallength >= 4.85 : Iris-virginica (43/0)
Size of the tree : 17
We can easily get completion by following Jython section on Completion function for GNU readline. I haven’t tried jythonconsole, but this approach works just fine.
But, of course we can work directly with Emacs since python-mode supports Jython right out of the box: in a Python buffer, just type M-x py-toggle-shells, and Emacs will switch to Jython as the default interpreter.
As for other goodies, we have access to Java-specific numerical libraries, like Apache Common Math or Java Numerics or Colt, in addition to JNumeric or GNU GSL jgsl–I haven’t tested any of these libraries at that time. However, there is no way to interface with extensions written in C for the standard Python. Another interesting project is jHepWork which is
an interactive environment for scientific computation, data analysis and data visualization designed for scientists, engineers and students.
Most of the above links come from the following Stack Overflow threads:
Finally, I should mention that for those interested in learning Python or Jython, The Definitive Guide to Jython is well worth a look; I wish that all projects are documented in the same way.