Diving Into Lisp for Statistical Computing
Well, it may seem like I feel either nostalgic of an era of statistical computing that I didn’t ever know or a little bit crazy to go back to Lisp while R has become lingua franca in statistics, but a wistful smile let me think I have a lot to learn going back to the 90’s and… xlispstat or Lisp Stat.
I always have the latest version of xlispstat installed on my Mac. Not that I’m using it on a regular basis, but just because I like playing with its spin-plot function. As it provides dynamic graphic capabilities and only require a working X11 installation, it always run (for me, at least) on my successive Macbook’s.
At that time, some authors felt there was room for further development around the Lisp-Stat project; other statistical projects were built on top of Lisp-Stat. Maybe the best known ones were VisTa and Arc which both featured some GUI functionalities.1
The definitive reference for learning Lisp Stat is of course Tierney, L. (1990), Lisp Stat: An Object Oriented Environment for Statistical Computing and Dynamic Graphics (John Wiley & Sons Inc), but there are also a lot of online resources. Here are some of my bookmarks:
- Lisp-Stat Information
- XLISP-STAT, A Statistical Environment Based on the XLISP Language
- Xlisp-Stat: UCLA Archive
- StatLib—XlispStat Archive
- Statistical Analysis Using XLispStat, R and Gretl: A Beginning
If you look at the lisp-stat repository on Luke Tierney’s website, you’ll soon get the idea: The project is somewhat still alive, but the latest src dated back from 2003/09/20 (version 3.52-20). However, it has not completely disappeared, and although there was a complete issue on the Journal of Statistical Software on the future of lisp as a statistical programming language,2 there’s still a growing interest in using Lisp for computational statistics. As an example, there is Lush (which I’d love to try if there were not so much compiling issues on OS X!). I also remember sending Ihaka and Lang’s famous paper, Back to the Future: Lisp as a Base for a Statistical Computing System (PDF), to a colleague of mine while he was thinking coming back to Lisp was no more than a bad joke. Many of John Floyd’s courses are based on Lisp Stat. Why is this so? I think there’re not in essence so much effective programming languages for computational statistics.
In reality, the idea of a statistical programming language is not a new one, and we can find great papers on that approach in the early 80’s. A well-know example is the S language, but see A Brief History of S (PS), by R.A. Becker, and Evolution of the S Language (PS), by J.M. Chambers. Now, there is R, which is supported by core members and a very active community of researchers. The idea is that we really need an interactive shell, and a true programming language, not Macro-based facilities and a lot of click-and-go options. After all, why would we need a GUI when we spent 60% of our time in a project managing data and doing exploratory data analysis? My very first criteria for using a statistical package is: Can I process my data saved in a text-based format and record my commands in a text editor?
But of course, now there’s Clojure and the incanter project that is under active development. So, what’s next? Actually, I’m thinking of working through both on some common data sets and see how it goes. My expectations are that I will learn a lot by getting into Lisp Stat philosophy and UCLA contributed extensions, and that this will facilitate my switch to Clojure/incanter. I am currently compiling some notes on Lisp for statistical computing. I hope I will be able to produce a draft version by the end of this summer, but as always this schedule is highly subjected to unexpected variations.
Anyway, here come the good news for Emacs users: Thanks to ESS, you can run Lisp Stat inside Emacs; just enter XLisp mode with M-x XLS and you’ll get a prompt and all the handy thinks that generally come with Emacs mode (history, parenthesis matching, etc.). Below is a screenshot I took during a short session:
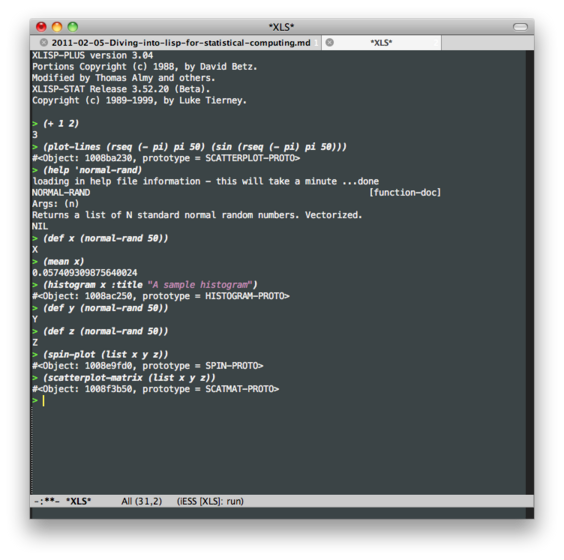
What’s so good with Lisp? Well, it is quite easy to run a regression model and to plot the residuals for the regression of x on y:
(def m (regression-model x y))
(send m :plot-residuals)
I particularly liked the intro paper by Jan de Leeuw, On Abandoning XLISP-STAT. ↩︎